
O Instituto Nacional de Pesquisas Espaciais (INPE) é um dos principais centros de pesquisa do Brasil, reconhecido mundialmente por sua atuação no monitoramento ambiental e climático. Entre 2016 e 2019, o instituto conduziu o projeto EBA (Estimativa de Biomassa da Amazônia), com o objetivo de mapear a biomassa do Bioma Amazônico de maneira mais precisa que as iniciativas anteriores.
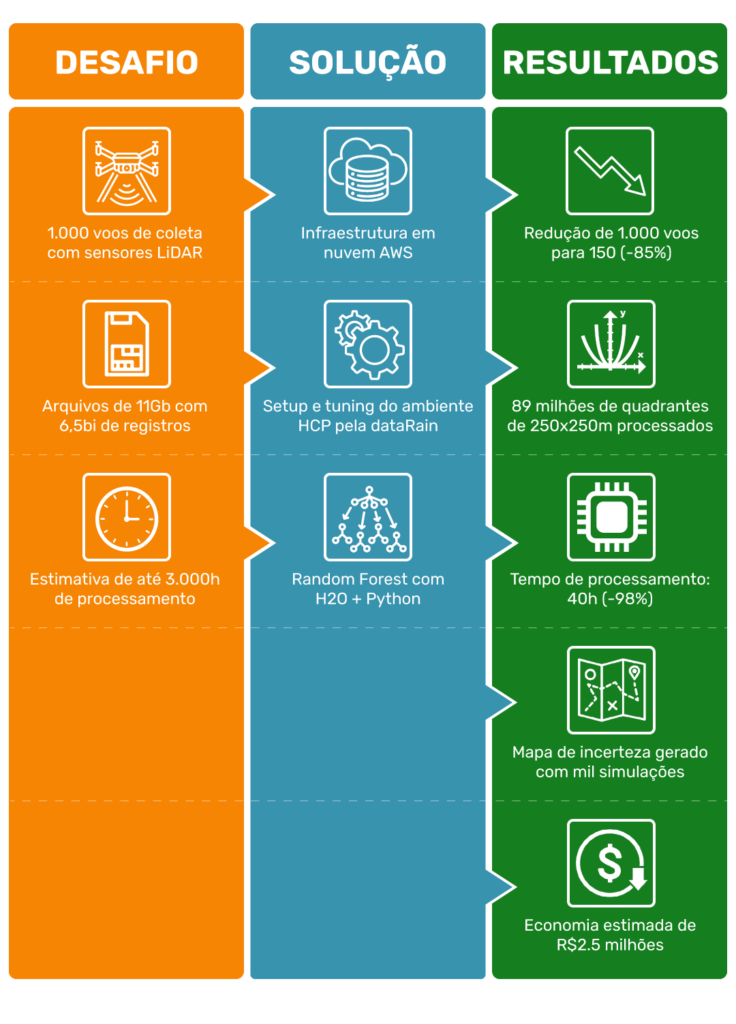
Foram feitos voos de coleta de dados usando sensores LiDAR aerotransportados (ALS).
Para extrapolar a biomassa coletada em campo para toda a extensão da Amazônia, o projeto combinou os dados LiDAR das campanhas aéreas com informações de satélites ópticos e de radar — incluindo espectro visível, infravermelho e micro-ondas. Essa etapa foi essencial para transformar medições pontuais em estimativas de larga escala e construir um modelo estatístico robusto.
Criado o mapa de biomassa, este passou a ser utilizado em diversas iniciativas como subsidiar o Inventário de Emissões de Carbono do Brasil, uma obrigação do país junto ao IPCC, Painel Intergovernamental sobre Mudanças Climáticas e as obrigações do Acordo de Paris.
Mil voos, bilhões de dados — e um gargalo
O INPE, por meio do Centro de Ciência do Sistema Terrestre (CCST), precisava transformar dados brutos em ciência de ponta. Cada voo de coleta de dados gerava um arquivo de 11Gbytes contendo cerca de 6,5 bilhões de registros de dados. Como foram pouco mais de 1.000 voos, isso resultou em cerca de 7 trilhões de registros de dados a serem processados.
Para a recepção, controle de qualidade dos dados recebidos e geração do mapa, foi usada uma máquina on-premise. O processamento final, o cálculo da biomassa para todo o bioma em pixels de 250m x 250m, demorou aproximadamente quatro horas na mesma máquina.
Pronto o mapa, restava um desafio: calcular o erro estatístico do mapa. Isso poderia ser feito de duas formas: calcular um coeficiente de erro para todo o mapa ou calcular a incerteza de cada pixel.
A segunda alternativa seria muito vantajosa porque produziria um segundo mapa, o de incerteza, mostrando como o erro estatístico estaria distribuído pela área estudada, o que possibilitaria determinar onde o modelo foi menos preciso, subsidiando estudos complementares.
Porém, para estimar a incerteza de cada pixel, era necessário gerar cerca de mil versões diferentes dos mapas de biomassa — uma exigência computacional intensa e indispensável para validar cientificamente os resultados. Mesmo com bons servidores locais, processar todo esse volume levaria mais de 3.000 horas.
Escalando o processamento com nuvem e machine learning
Com o suporte da dataRain e da AWS, o projeto ganhou escala e velocidade. A arquitetura baseada em nuvem foi composta por serviços como Amazon EC2 HPC (4 instâncias com 64 vCPUs e 256 GB RAM cada), Amazon S3, EBS, Route 53, VPC e EFS.
A equipe da dataRain foi responsável pelo setup e tuning do ambiente de alta performance. A modelagem estatística utilizou o algoritmo Random Forest, implementado com a plataforma H2O e Python, para calcular a incerteza de cada pixel do mapa — viabilizando, assim, a geração do mapa de incertezas da biomassa amazônica.
Essa abordagem foi fundamental para estimar a confiabilidade dos dados em larga escala, um passo técnico essencial para validar os resultados científicos do projeto.
Redução de tempo e integração com o ambiente do INPE
O tempo de processamento, que antes levaria entre 2.000 e 3.000 horas, caiu para apenas 40 horas com a infraestrutura em nuvem. Além disso, o INPE consolidou todo o trabalho em seu servidor local em apenas dois dias, integrando facilmente os dados processados na AWS ao seu ambiente interno.
Ganho financeiro com menos voos e mais escala
“Para estimar a incerteza do nosso conhecimento sobre a biomassa da Amazônia, eu precisava gerar mil mapas. Com a estrutura que tínhamos, isso levaria de 2 a 3 mil horas. Com o apoio da AWS e da dataRain, conseguimos processar tudo em apenas 40 horas, e consolidar os resultados no nosso servidor em dois dias. Esse trabalho nos deu uma medida concreta do nosso desconhecimento da floresta. Além disso, permitirá que o mapa possa ser atualizado sem a necessidade de se repetir os mil voos de coleta de dados, voando-se apenas sobre as áreas onde a incerteza foi maior. Isso reduzirá muito os custos na etapa mais cara e complicada da elaboração do mapa, possibilitando a atualização com cerca de 15% dos voos iniciais, que custaram cerca de R$3.000.000,00 à época.”
— Mauro Assis, pesquisador do CCST durante o projeto EBA
Legado científico com impacto estratégico
Concluído em 2019, o projeto deixou um legado técnico e científico: a floresta foi mapeada com mais precisão e responsabilidade. Os dados gerados seguem sendo referência para pesquisas, inventários de carbono, políticas públicas e discussões internacionais sobre clima.
Esse conjunto de dados científicos apoia decisões sobre conservação, precificação de carbono e financiamento climático. Um exemplo claro de como nuvem, ciência e colaboração transformam conhecimento em impacto real.
“O legado do EBA: dados de alta qualidade que apoiam decisões estratégicas sobre clima, conservação e financiamento verde.”
Gostou do Conteúdo?
Você pode falar com um de nossos especialistas do setor